

 Le W3C entérine les DRM
Le W3C entérine les DRM
Jeudi 03 octobre 2013
Voilà. Le W3C continue sa poussée en intégrant officiellement le draft de norme sur les DRM dans le groupe de travail HTML. Le draft s'appelle EME (Encrypted Media Extensions): http://www.w3.org/TR/encrypted-media/. C'est une API permettant de standardiser l'interfaçage des navigateurs et des systèmes de DRM. Dans la pratique, vous ne pourrez pas enregistrer les vidéos. Le navigateur passera le contenu chiffré au module DRM qui se chargera de décoder les trames.
Histoire de bien foutre le bordel: Notez que ce standard n'impose pas un système de DRM particulier, mais juste une API. Ce qui veut dire que chacun va se fendre de son petit système de DRM, qui sera différent d'un vendeur à l'autre, d'un système d’exploitation à l'autre, d'un site à l'autre, d'un navigateur à l'autre. De quoi - en plus d'être emmerdé par les DRM - morceler un peu plus le web. Vous trouviez que c'était déjà le bordel entre MPEG4, WebM/VP8, OGG/Theora, MP3 et Vorbis ? Vous n'avez encore rien vu. Le plus beau, c'est que ça n'empêchera même pas le piratage des œuvres. (C'est pas comme si la TOTALITÉ des DRM existants avaient été cassés, hein ?).
Certes, cette norme est uniquement orientée vidéo, mais après la vidéo, que croyez-vous qu'il va se passer ? Il y a plein de monde qui attend à la porte pour avoir sa petite couette confortable de DRM: Les photographes pour empêcher la "copie" de leurs photos, les maisons de disque pour restreindre l'écoute, les agences de presse et maisons d'édition pour empêcher le vilain copier-coller, les webmasters neuneus pour "protéger" leur code HTML/javascript.
Vous croyez que je plaisante concernant le code HTML et javascript ? Pas du tout: Il y a déjà un groupe de travail au W3C sur le sujet. Imaginez un monde où votre navigateur ne va plus exclusivement vous obéir, mais va - sur certaines de ses fonctions - obéir à des tiers. Imaginez le jour où vous ne pourrez même plus enregistrer une image ou voir le code source d'une page HTML. (Si ça se réalise, je présume que ces restrictions concerneront également les extensions pour navigateurs, ce qui les empêcherait d'accéder au contenu de la page... oh regardez, POUF, plus de vilain AdBlockPlus qui vient nous arracher le pain de la bouche, la vie est bêêêêêllle !). Les membres du W3C sont déjà en train d'y réfléchir.
Voilà comment je vois le web de demain: Les géants du Minitel 2.0 proposeront ça dans leurs services (par exemple une option dans YouTube pour empêcher l'enregistrement des vidéos, ou chez Flickr pour empêcher la copie des photos (spaceballs !(1)). Et je présume que si votre navigateur n'est pas EME-compliant, vous ne pourrez pas lire ces vidéos ou voir ces photos. Soit vous acceptez les DRM, soit une partie du web ne vous sera plus accessible. Et comme ça sera W3C-compliant, ils pourront vous jeter avec dédain avec la bonne conscience d'avoir respecté les normes officielles du ouèbe. En intégrant EME au sein du groupe de travail HTML, c'est la voie dans laquelle s'est engagé le W3C.
Le W3C n’œuvre plus exclusivement pour un web ouvert. C'est terminé. Je pense que l'ouverture du web, l'interopérabilité, est condamnée à moyen terme. Vous vous demandez comment, comment le W3C a pu accepter ça ? C'est simple: regardez la liste de ses membres.
Bien plus criant: Regardez qui sont les éditeurs de cette nouvelle norme du W3C: David Dorwin (Google), Adrian Bateman (Microsoft), Mark Watson (Netflix). Vous leur faites vraiment confiance pour œuvrer pour le bien de tous ?
C'est triste, mais il est temps de prendre du recul par rapport au W3C. Quand il était encore jeune, internet n'était pas un tel enjeu économique et le W3C remplissait alors bien son rôle. Maintenant qu'internet est un lieu où se brassent des sommes absolument colossales, les membres du W3C ont des intérêts commerciaux bien trop importants et ils ne se gênent plus pour pousser le W3C dans la direction qui arrange leur business. En même temps, à quoi je m'attendais, franchement ?
Vous croyez que je vois tout en noir ? L'avenir nous le dira. Si j'ai raison, alors le web du futur pue des pieds. (Voilà, ça c'était pour les petits mots grivois de circonstance.)
Mise à jour 15 janvier 2013: Complément: La MPAA rejoint le W3C. Les spécifications qui ont abouti à la norme EME sont secrètes.
(1) L'allusion n'est pas facile à comprendre si vous n'avez jamais plongé dans le code HTML des pages de Flickr.
Chers sites web soit-disant «sociaux»
Jeudi 08 aout 2013
 Votre slogan est «Partager», mais vous ne voulez pas vraiment qu'on partage. Vous voulez nous garder à l'intérieur de votre cage dorée. C'est pour cela que vous avez passé votre temps à retirer de vos pages les liens vers les flux RSS, les cachant au fin-fond de votre site, ou les supprimant purement et simplement, en les remplaçant par des API propriétaires rabougries ou démentielles. ET BIEN MERDE.
Votre slogan est «Partager», mais vous ne voulez pas vraiment qu'on partage. Vous voulez nous garder à l'intérieur de votre cage dorée. C'est pour cela que vous avez passé votre temps à retirer de vos pages les liens vers les flux RSS, les cachant au fin-fond de votre site, ou les supprimant purement et simplement, en les remplaçant par des API propriétaires rabougries ou démentielles. ET BIEN MERDE.
Vous n'êtes pas "social" quand vous entravez le partage en retirant RSS. Vous êtes heureux de voir vos utilisateurs créer du contenu pour votre écosystème, mais vous ne voulez pas voir ce contenu sortir de chez vous - un contenu qui ne vous appartient même pas. Google Takeout est juste de la poudre aux yeux. Nous voulons que les données circulent, nous voulons RSS.
Nous voulons partager avec nos amis, en utilisant des protocoles ouverts: RSS, XMPP, peu importe. Parce que personne ne veut qu'on lui fourgue de force votre service avec votre application utilisant votre API. Les amis devraient pouvoir choisir les logiciels et services qu'ils veulent.
Nous sommes en train de reconstruire les ponts que vous avez volontairement détruits.
Sortez-vous les doigts du cul: Remettez RSS en place.
(Le même article en anglais là.)
Dear so-called «social» websites
Jeudi 08 aout 2013
Your catchword is «share», but you don't want us to share. You want to keep us within your walled gardens. That's why you've been removing RSS links from webpages, hiding them deep on your website, or removed RSS entirely, replacing it with crippled or demented proprietary API. FUCK YOU.
You're not social when you hamper sharing by removing RSS. You're happy to have customers create content for your ecosystem, but you don't want this content out - a content you do not even own. Google Takeout is just a gimmick. We want our data to flow, we want RSS.
We want to share with friends, using open protocols: RSS, XMPP, whatever. Because no one wants to have your service with your applications using your API forced-feeded to them. Friends must be free to choose whatever software and service they want.
We are rebuilding bridges your have wilfully destroyed.
Get your shit together: Put RSS back in.
(Same article in French here.)
 Grosses images et petits débits
Grosses images et petits débits
Mardi 30 juillet 2013
Je suis issu d'une époque pré-ADSL où le top de la vitesse était le modem 56K. Soit environ 5 kilo-octets par seconde. Forcément, ça laisse des traces, comme cette obsession maladive d'optimiser les images. Je ne parlerai pas ici d'optimisation de la taille de vos fichiers JPEG (que ce soit en diminuant la résolution ou en jouant avec le pourcentage de qualité JPEG ; Il y a des outils pour ça). Je vais parler ici d'astuces pour donner l'impression que la page se charge plus vite.
L'astuce du pauvre
A l'époque des modems RTC, il était courant pour les pages web d'ajouter un attribut "lowsrc" aux balises images. L'attribut lowsrc est identique à src, mais pointe sur une image très basse résolution (généralement une image de moins de 10 ko). Exemple:
⋖img lowsrc="chaton-low.jpg" src="chaton.jpg" width="1024" height="768">
Le navigateur ayant chargé rapidement la petite image spécifiée dans lowsrc, il affichait immédiatement la page, même si les images pleine résolution n'avaient même pas commencé à se charger (Bien sûr, n'oubliez jamais d'indiquer en complément width et height, hein ?). Certes cela faisait au final plus de données à télécharger, mais la page s'affichait malgré tout plus vite.
C'est tout l'intérêt de la vitesse perceptive par rapport à la vitesse effective. C'est purement psychologique, et vous voulez que l'internaute ai l'impression que la page se charge vite.
De nos jours, ce n'est plus trop utilisé. D'abord parce qu'on a des débits de folie, mais aussi parce qu'on a désormais le JPEG progressif.
L'astuce du riche
La particularité du JPEG progressif est que l'image est entièrement affichable même si on a reçu que 3% du fichier. L'image s'affiche alors immédiatement en entier, et se raffine peu à peu.
Message subliminal:CONVERTISSEZ TOUS VOS JPEG EN PROGRESSIF S'ILS DOIVENT ÊTRE PUBLIÉS DANS UNE PAGE WEB.
Non vraiment j'insiste. Le JPEG progressif c'est bon, mangez-en. Dès que votre JPEG dépasse 10 ko, convertissez-le en progressif. Il n'y a aucune perte de qualité et le fichier sera plus petit (dans la majorité des cas).
Voici ce que donne le chargement d'un JPEG standard (non-progressif):

5,2 ko chargé (3%)

16 ko chargé (9 %)

108 ko chargé (60 %)
Et la même chose en JPEG progressif:

5,2 ko chargé (3 %)

16 ko chargé (9 %)

108 ko chargé (60 %)
Du coup, avec toutes les images en JPEG progressif, le navigateur peut très rapidement calculer et afficher la page, même si votre joli JPEG de 2 Mo n'est pas encore chargé en entier. Toutes vos pages donneront l'impression de se charger plus vite, et ce, sans manipulation supplémentaire dans votre page (ni au niveau du code html, ni au niveau du javascript).
Le second effet kiss-cool, c'est que pour une même qualité JPEG, le progressif est généralement plus petit (Dans notre cas: 183 260 octets pour le standard, 176 202 octets pour le progressif, pour une qualité d'image strictement identique).
{kind=link}
{kind=link}
Le troisième effet kiss-cool que j'ai constaté (corrigez-moi si je me trompe), c'est que certaines LightBox javascript semblent obtenir plus rapidement la taille de l'image, et affichent donc plus rapidement les images dans les galeries (comme la mienne). C'est tout bénef.
Et là, c'est le drame...
Tout va bien ? Il y a encore un petit soucis. Rien n'est plus agréable que mettre un bon gros JPEG en fond d'une page web avec un background: url(...), n'est-ce pas ?
Mais là, mauvaise surprise: Les navigateurs se foutent royalement que votre JPEG soit progressif: Ils ne l'afficheront que lorsqu'il sera entièrement chargé (sauf Chrome). Du coup votre page va rester avec un fond noir pendant plusieurs secondes. Même si ce n'est pas sale, c'est assez laid. Mais on peut ruser.
En fait, dans background il est possible de spécifier plusieurs images. Par exemple, j'ai fait:
background: url("background.jpg") no-repeat, url("background-fast.jpg") no-repeat;- background-fast.jpg est un petit jpeg en 640x480 de 20 ko. Le chargement sera quasi-immédiat.
- background.jpg est l'image pleine résolution: 1920x1080 et 545 ko.
Les navigateurs chargeront en premier les images spécifiées en fin de ligne (background-fast.jpg) et chargeront ensuite vers la gauche (background.jpg).
Le résultat ? L'image de fond semble s'afficher immédiatement, ce qui visuellement est bien moins perturbant. Vous pouvez voir le résultat dans cette page (Cliquez sur le bouton rechargement de page de votre navigateur en maintenant la touche MAJ enfoncée pour forcer le re-chargement de tous les éléments de la page). C'est quand même bien plus agréable.
Pensez à ceux qui ont des débits merdiques, et n'oubliez jamais:
Vous pouvez convertir vos JPEG existants en progressif sans perdre en qualité.
 Une journée (chaude) à Paris
Une journée (chaude) à Paris
Mardi 16 juillet 2013
Hello.
Hier j'étais à Paris. Ça a été l'occasion de rencontrer certains d'entre vous (Kevin Merigot, Hoper et sa femme, Tommy et tous les autres) . Ça a été vraiment très sympa :-) J'avoue que le petit comité d'accueil à la gare (avec les pancartes) était intimidant. Nous étions 15 au restaurant et - ah ! - je crois que Kevin aura une photo de moi à vous montrer ;o) Il a fait très chaud, et heureusement que le serveur a bien voulu nous remettre en salle parce que la terrasse était tout simplement insupportable avec les travaux juste à côté. Ça fait plaisir de pouvoir mettre un visage sur certains noms. Merci à tous. Nous avons squatté le restaurant presque jusqu'à 17 heures, à discuter de tout et de rien.
Je me suis éclipsé pour me rendre dans les locaux de Mozilla France, où j'ai été invité par FING à une discussion sur la réappropriation des données personnelles, avec des gens de chez Mozilla, de la CNIL, de CozyCloud, de Privowny et plein d'autres personnes intéressantes. J'ai enfin rencontré Stéphane Bortzmeyer (avec son T-Shirt Framasoft :).
Je ne peux pas vous rapporter la totalité de la discussion, alors voici quelques points clés:
FING a lancé une initiative afin que les internautes se ré-approprient leurs données personnelles: téléphonie, assurance, supermarchés et autres. Le but est de convaincre les acteurs de privés de donner aux internautes un accès brut à toutes les données les concernant, ce qui permettra par la suite aux internautes de les exploiter eux-même pour de nouvelles applications.
Il y a encore beaucoup de problèmes à résoudre: comment convaincre les acteurs privés et publiques ? Sous quelles conditions récupérer ces données ? (sachant que pour la plupart ce sont des opérations très manuelles lorsqu'elles sont demandées). Comment authentifier les utilisateurs ? (l'adresse email ou postale ne suffit pas). Sous quel format récupérer ces données ? (utiliser des standards existants ou utiliser le format brut fourni par l'entreprise ? Transformer les données ?). Comment les exploiter ? (quelles applications ? comment y accéder ? comment les déployer ?)
CozyCloud apporte un début de réponse: Ils proposent un cloud personnel - un silo de données personnel - où vous pourrez stocker toutes ces informations, et offre une plateforme qui permet de développer des applications pour exploiter ces données. Une sorte de Google AppEngine, mais ouvert et hébergé où vous le voulez. Il gère actuellement diverses applications: mail, contacts, agenda, notes, photos, flux RSS, ToDo, Bookmarks, nirc. (Actuellement les sources sont sur GitHub et tournent sous NodeJS. Pour simplifier l'installation, ils fourniront à terme des machines virtuelles.). Et vous pouvez développer de nouvelles applications pour CozyCloud, dans le langage de votre choix. L'intérêt de CozyCloud est que ces applications collaborent sur votre silo de données personnel qui peut être hébergé chez vous. Bien sûr cela pose aussi des questions sur le modèle de sécurité des applications. Mais l'ensemble est assez bien pensé.
Histoire d'avoir de la matière FING lancera une opération avec la poignée d'entreprises qui ont accepté de se prêter au jeu et 300 personnes volontaire au mois d'août, afin de voir un peu ce qui marche et qui ne marche pas, et comment tout le monde ressent l'expérience. Des concours seront probablement lancés pour inciter à la création d'applications innovantes.
Oui, tout cela est un peu effrayant: Voir toutes vos données, accumulées depuis tant d'années par les entreprises avec qui vous avez eu affaire doit donner le vertige. Mais c'est justement un bon moyen d'en reprendre le contrôle et de les exploiter au mieux, pour votre plus grand bénéfice (Imaginez un exemple tout simple: Surveiller l'augmentation des prix de votre supermarché habituel, et comparer avec d'autres). Mais les applications sont encore à imaginer.
Il se pourrait même que l'accès à vos données personnelles devienne un enjeu. Imaginez: Entre une entreprise qui vous donne le plein accès à toutes les données qu'elle stock sur vous et une autre qui refuse, à laquelle ferez-vous le plus confiance ? Vous avez deviné: Cela pourrait devenir un argument de vente majeur pour les entreprises, qui année après année perdent la confiance de leurs clients (malgré les trombes de cartes fidélité). (Pourquoi croyez-vous que Google a créé Google Takeout ?)
Il y a encore beaucoup de questions, beaucoup de problèmes à résoudre et d'expériences à réaliser avant de concrétiser tout cela, mais c'est prometteur.
Privowny de son côté propose une extension Firefox pour protéger votre vie privée: Non seulement il bloque les traqueurs (à l'image de Ghostery dont je vous rebat les oreilles), mais en prime il permet de tracer quelles information vous avez donnée à qui: numéro de téléphone, adresse postale, etc. Vous voulez savoir à quels sites vous avez donné votre numéro de téléphone ? Privowni vous affichera la liste (bien sûr il n'enregistrera qu'à partir du moment où il est installé).
En prime, il vous affiche les centres d'intérêt que les réseaux publicitaires ont identifié chez vous, et propose aussi un service d'email jetable permettant de ne pas avoir à donner son adresse email réelle (et prochainement aussi des numéros de téléphone jetables, pour éviter d'avoir à donner son véritable numéro de téléphone).
Toutes ces données sont chiffrées côté client avec un système clé publique/clé privée. Privowny ne peut donc pas voir le contenu des données chiffrées. Vous pouvez à tout moment choisir de chiffrer ou non une donnée, ou l'effacer. Vous pouvez également à tout moment exporter la totalité de vos données au format jSon et tout effacer chez Privowny. Côté business model, Privowny envisage des services payants supplémentaires (modèle freemium). Un exemple ? Si vous voulez effacer ou rectifier une donnée vous concernant, Privowny se chargera pour vous de faire la démarche auprès de l'entreprise. Privowny réfléchit également à l'ouverture des sources de son service.
Il sera intéressant de voir comment tout cela évolue.
Quant aux locaux de Mozilla France, c'est la grande classe.
 Le plus stupide DRM jamais inventé
Le plus stupide DRM jamais inventé
Lundi 08 juillet 2013
Les DRM sont des techniques dont le bût est de contrôler l'utilisation des fichiers numériques. En très grande majorité, elles essaient surtout d'empêcher la copie des bits (Ce qui - il faut l'avouer - est déjà incroyablement idiot quand on sait comment fonctionne internet ou n'importe quel ordinateur: Ce ne sont rien d'autre que des machines à copier des bits).
Mais je crois avoir trouvé le plus stupide DRM de l'histoire: Une société a récemment mis en place des DRM sur les eBook consistant à modifier légèrement les exemplaires vendus à chaque client: un espace par ci, un retour à la ligne par-là. Le but étant, probablement, de vous attaquer en justice si c'est votre copie du livre qui se retrouve sur les réseaux de partage. (Cette technique n'est d'ailleurs pas nouvelle.)
C'est une idée incroyablement stupide. Il peut y avoir des tas de raisons qui font que votre copie se retrouve dans la nature: Ordinateur revendu (et disque dur non effacé), clé USB perdue, ordinateur prêté, volé, piraté... Dans tous les cas, cette entreprise met en place dans l'esprit de ses clients potentiels une équation très simple, qui est l'une des plus mauvaises décision business que j'ai pu voir, encore pire que d'essayer de bloquer techniquement la copie:
Il ne faut pas être devin pour savoir ce que feront les clients potentiels: Ils iront pirater le livre.
Là il ne s'agit plus juste d'être emmerdé par les DRM (impossibilité de lire parce que les serveurs sont en panne ou la connexion internet coupée, impossibilité de le transférer sur un autre système, blocage intempestifs, écrans d'avertissement...), il s'agit d'être menacé légalement dès le moment où vous êtes client. Bravo les gars.
(Hé vous avez vu ? Je fais des efforts pour sortir de Shaarli !)
 Le double #FAIL du site web de WinSCP
Le double #FAIL du site web de WinSCP
Lundi 08 juillet 2013
Voulant télécharger WinSCP (un très bon client sftp/ftp pour Windows), je vais sur le site officiel et comme une mule je clique sur le bouton "Télécharger":

Raté: Ce n'est pas le bouton de téléchargement de WinSCP ! C'est une publicité qui me renvoie sur un site qui sent le fennec faisandé (un webplayer douteux qui vous enfourne rapidement un abonnement si vous oubliez d'annuler la période d'essai). Le bon lien était "la page de téléchargement de WinSCP" un peu au dessus.
Une fois arrivé sur la vraie page officielle de téléchargement de WinSCP, second #FAIL:

L'énorme bouton "Télécharger" ne permet pas non plus de télécharger WinSCP.
Webmasters, si vous mettez de la publicité sur votre site, par pitié CONTRÔLEZ UN MINIMUM LE NIVEAU DE PUS QUE CRACHENT CES PUSTULES PUBLICITAIRES. Gagner de l'argent, c'est ok, mais il y a quand même un minimum de respect à avoir pour vos visiteurs. (Personnellement, quand j'avais encore de la publicité sur mon site, je leur faisais une chasse implacable. Je sais, c'est terriblement chiant et fastidieux, mais c'est un choix.)
Et après il y a encore des webmasters qui se plaignent des bloqueurs de publicité ? O'RLY ? Quand on jette de la merde à la face des visiteurs, il ne faut pas leur reprocher de vouloir s'en protéger.
D'ailleurs pourquoi «ça sent le fennec», hein, d'abord ? Quelqu'un a déjà reniflé un fennec ? En plus c'est mignon tout plein un fennec.
EDIT: Un me les lecteurs me fait dire que - si si - ça pue, un fennec :-D
L'échec épique de la Xbox One
Lundi 17 juin 2013
Je sais, ça a déjà été dit et re-dit, mais je tenais à essayer de résumer la merde dans laquelle s'est mise Microsoft avec les restrictions de la Xbox One:
- Plus chère que la PS4 de Sony, et moins puissante.
- Si la console n'est pas branchée toutes les 24 heures à internet, elle se bloque. Vous pensiez emporter votre console en vacances ou en week-end ? Oubliez.
- Vous ne pouvez pas prêter ni donner vos jeux. (EDIT: Il se pourrait que Microsoft permette le prêt.)
- Impossible également de les revendre (sauf si l'éditeur du jeu le permet - haha bonne blague).
- Blocage régionaux (21 zones) comme pour les lecteurs DVD.
- Où sont les jeux ? Il n'y a pratiquement rien. Les concepteurs de la Xbox ont d'abord pensé à la télé avant de penser aux jeux.
- Le Kinect vous observe et vous écoute 24 heures sur 24.
- Le Kinect n'est pas désactivable dans les options. Corrigé: il le sera.
- Si vous couvrez la caméra de la Kinect, les jeux se bloquent.
- Si vous êtes banni par Microsoft, vous perdez les jeux que vous avez achetés vous ne pourrez plus jouer en ligne. (Démenti de Microsoft: Si vous êtes banni, vous pourrez continuer à jouer en solo.)
Microsoft a réussit à tout faire foirer avant même la mise sur le marché de sa console. Certes Microsoft perdait déjà de l'argent avec la Xbox et la Xbox360, mais là comme plantage en beauté, c'est épique. Je ne comprend pas, vraiment. Il y a eu une fuite des cerveaux chez Microsoft, ou bien ils n'ont juste pas suivit ce qui s'est passé ces 10 dernières années sur le net ?
Entre l'échec de la Xbox One, le semi-échec de Windows 8, la grogne des utilisateurs, l'aliénation des développeurs, ses tablettes qui se vendent mal, les smartphones à base de WindowsRT qui ne se vendent pas mieux, mais que fout Microsoft ? C'est le festival des mauvaises décisions.
Microsoft ressemble à Apple quand ce dernier était sur sa pente descendante. Saura-t-il ne pas couler ?
Mise à jour 19 juin 2013: Microsoft a décidé de faire machine arrière: Une seule connexion initiale sera exigée, après quoi vous pourrez jouer sans avoir à vous connecter toute les 24 heures à internet. Il sera également possible de prêter ou revendre les jeux, sans restriction. Et Microsoft lève aussi les restrictions régionales. Tout cela c'est bien, mais il a quand même fallu que tout le monde hurle pour que Microsoft comprenne. (source)
 Le grand méchant DMCA et les 3 petits LOLs
Le grand méchant DMCA et les 3 petits LOLs
Dimanche 28 avril 2013
Mitsu s'est complètement fait délister de Google. Le site entier. Moi c'est plus soft (juste une URL), mais amusant.
Plusieurs internautes m'ont en effet signalé qu'une URL de mon site avait été dé-listée de Google sur plainte DMCA. Pour ceux qui ne connaissent pas, DMCA est une loi américaine de protection du droit d'auteur qui stipule d'un hébergeur ou moteur de recherche doit supprimer l'URL incriminée sur simple déclaration sur l'honneur de l'ayant-droit présumé.
Une URL de mon site a donc été délistée de Google sur plainte DMCA d'un ayant-droit, et Google m'a transmis la plainte:

Le message contient l'URL de la lettre reçue par Google. Elle se trouve là: http://www.chillingeffects.org/notice.cgi?sID=911655.
LOL n°1: Cherchez bien. Non cherchez mieux. Oui, je sais: Mon nom de domaine n'est mentionné nulle par dans la lettre. Alors pourquoi Google m'a-t-il délisté et fait suivre cette plainte ?
LOL n°2: J'ai beau prendre l'URL en question (http://sebsauvage.net/paste/?ae60be9cec5e00b8) et la coller dans n'importe quel navigateur, non vraiment, ça ne me donne aucun document qui me semble relever du droit d'auteur. J'ai donc remplis avec plaisir un formulaire de contre-déclaration.
Oh... vous voulez dire que Google (ou l'ayant-droit) aurait omis d'ajouter la clé de déchiffrement privée ZeroBin dans l'URL ? Non, bien sûr: S'ils avaient mis cette clé de déchiffrement, cela aurait été un document privé. Les ayants-droit ne peuvent demander le délistage d'un document privé, n'est-ce pas ?
LOL n°3: Google a donc délisté juste cette URL. Ils auraient pu délister entièrement toutes les URLs en http://sebsauvage.net/paste/
En fait, c'est exactement ce que je veux, je veux que les moteurs de recherche n'indexent rien du tout de tout ce qui est dans http://sebsauvage.net/paste/
Bonne séance de LOL, non ?
Soyons clair: Je ne suis pas contre le droit d'auteur. Je suis moi-même auteur de centaines de documents, images et logiciels. Mais je suis contre cette défense débile, abrutie, automatisée et sans-tête du droit d'auteur, et je lutterai contre.
En tous cas, c'est la première plainte que je reçois concernant ZeroBin, et elle est nulle et non avenue.
Mise à jour 16 mai 2013: Google a répondu à ma contre-déclaration:Hello,
Pursuant to the counternotice you sent to us on 28/4/2013, we have reinstated the following URL(s) in the Google index: http://sebsauvage.net/paste/?ae60be9cec5e00b8 .
Regards,
The Google Team
L'affaire est donc close.
Puisqu'il faut un exemple...
Dimanche 17 mars 2013
A quel point cela pourrait-il être compliqué de s'installer un substitut de Google Reader ? Puisqu'il faut un exemple, prenons le projet de Tontof, KrISS Feed.
1) Mettez le fichier index.php dans un répertoire sur votre site web (Oui, il y a juste un fichier à installer).
2) Ouvrez l'URL et choisissez un login/mot de passe.

3) Importez le fichier OPML que vous avez récupéré de Google Reader ou autre:

4) Dans la configuration, activez la mise à jour par Javascript:

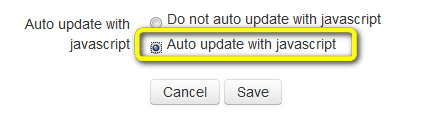
5) C'EST TERMINÉ. Vous avez un lecteur de news à vous. La mise à jour des flux se fera automatiquement en tâche de fond.

Alors, c'était compliqué ? Ça valait le coup de se faire des nœuds au cerveau ?
En prime tout peut se piloter avec des raccourcis clavier. On peut configurer pas mal de choses. Si vous préférez la vue dépliée et sans la liste des flux à gauche, c'est également possible:
Franchement, si vous cherchez encore une excuse pour vous aller vous inscrire chez un autre service fermé, c'est que vous êtes une feignasse.
EDIT: Pour KrISS Feed, il faut php 5.3 minimum.
 Arrêtez de pleurer Google Reader: Hébergez un lecteur RSS chez vous
Arrêtez de pleurer Google Reader: Hébergez un lecteur RSS chez vous
Vendredi 15 mars 2013
Posterous a été racheté par Twitter qui va le fermer dans moins de deux mois. POUF! Plus rien. Même chose pour Feeddemon. Et Google a annoncé la fermeture de Google Reader au 1er juillet. Et d'un seul coup, tout le monde se réveille: Oh mon Dieu, qu'est-ce qu'on va faire maintenant ??? Bou-hou-houuuu...
Oh, non mais vous êtes sérieux, là ? Ça y est, c'est panique à bord ? C'est une blague, non ? Vous êtes à ce point dépendant d'une simple appli ?
Et quelles sont les solutions proposés en remplacement, massivement ? D'autres services fermés à base de logiciels privateurs. Et dans deux ans quand ils fermeront, ça sera le même cortège de pleureuses.
Rappelez-vous: VOUS ÊTES SUR INTERNET. Internet n'est pas un minitel dirigé par Google. N'importe quelle machine du réseau peut se transformer en serveur en deux minutes. On trouve des espaces d'hébergement gratuits ou payants à la pelle: Merde, c'est quand même pas la mort de prendre quelques minutes pour installer un lecteur opensource RSS sur votre espace web. Alors oui, ça va nécessiter un peu d'efforts: installation et changement des habitudes. Mais ça m'évitera d'entendre ce concert de geignards (Opera, Opera, pourquoi ton Unite a si brillamment échoué ??? C'était une idée de génie qui aurait pu réhabiliter le "serveur chez soi", même pour les neuneus.)
Pour les lecteurs RSS en ligne, ce n'est pas le choix qui manque (Bien sûr certains sont plus faciles à installer que d'autres).
- Leed: Site, démo
- KrISS Feed: GitHub, démo
- FreshRSS: Site, GitHub
- Aeres: Site, démo
- Miniflux: Site, GitHub
- selfoss: Site
- RSS Lounge: Site
- cartulary: GitHub
- RSSMiner: Site, GitHub
- Gregarius: Site
- NewsBlur: Site (payant), GitHub
- FeedHQ: Site, GitHub
Et j'en oublie sûrement.
Là au moins, personne ne viendra vous fermer le service ni même surveiller ce que vous lisez: Les données et l'application sont chez vous.
Arrêtez de pleurnicher et prenez vos applications et vos données en main !
Tant qu'on y est, deux lectures salutaires: Google et la webisation des intertubes, Google : la mise en place de l’aspirateur à données personnelles
 Patate chaude
Patate chaude
Jeudi 21 fevrier 2013
Bon allez, je réponds à l'appel d'Alda (mais je ne continuerai pas la chaîne -- j'ai une aversion envers les messages qu'on me demande de forwarder à X personnes.)
1. À ton avis pourquoi il y a moins de femmes chez les geeks, libristes, hacker et hardcore-gamers de tous bords qu’ailleurs ?
Je ne pense pas que la proportion écrasante de mâles soit spécifique à l'informatique. On retrouve le même genre de tendance chez les politiques, chefs d'entreprise ou chefs étoilés. C'est juste notre culture historique machiste que nous traînons comme un boulet. Si on croit progresser sur l'acceptation de l'homosexualité dans la société, il faut bien voir que les femmes sont encore traitées comme de la merde même de nos jours (Il suffit d'observer le comportement honteux des députés à l'assemblée nationale).
Et encore: Dans nos sociétés occidentales, malgré ces comportements à la con, on peut considérer que la femme est admirablement bien traitée par rapport à la majorité des pays de cette planète (où certaines se prennent de l'acide dans la gueule pour avoir osé apprendre à lire).
Ne jetons pas la pierre aux geeks/gamers: Je ne pense pas que ce problème leur soit spécifique. La société est lente changer, très lente.
2. Tu ne penses pas que parfois, il faut vraiment protéger les enfants ?
Oui, bien sûr, la question ne se pose même pas. Mais: de quoi, et comment ? Vaste question.
J'ai toujours eu naturellement tendance à protéger mes enfants, mais de la mauvaise manière: En leur évitant les risques au lieu de leur apprendre à les gérer. C'est une erreur (et merci à ma femme de me l'avoir fait comprendre). Par exemple, les produits ménagers, chez moi, ne sont pas sous clé: J'ai expliqué à mes enfants que c'était dangereux et qu'il ne fallait pas y toucher. Et il n'y ont pas touché.
Laissez-moi expliquer mon choix par un exemple: Des parents règlent leur chauffe-eau pour éviter que leurs enfants se brûlent s'ils mettent l'eau chaude à fond. L'intention est louable: Réduire le risque de brûlure. Et que se passera-t-il quand ils iront faire un tour chez papy-mamie ? Ils auront pris l'habitude de mettre l'eau chaude à fond et se brûleront. Le résultat est l'opposé de ce que était escompté. Qu'aurait-il fallut faire ? Leur expliquer les dangers et leur apprendre à les éviter eux-même.
Bien sûr il est hors de question d'exposer les enfants à des risques inutiles, mais c'est la même chose dans beaucoup de domaines: L'éducation est le seul salut. (Parce que nous ne serons pas toujours là.)
(Après, je n'ai bien sûr pas abordé d'autres problèmes plus graves, comme la violence envers les enfants.)
3. La liberté d’expression, jusqu’à quel point ?
Question intéressante. Quand j'ai commencé à m'intéresser à Freenet, j'ai voulu connaître les raisons qui ont motivé les auteurs de ce logiciel de P2P anonyme, et je dois dire qu'au début j'ai été choqué. Leur crédo ? La liberté d'expression doit être totale, sans aucune censure possible, sans quoi ce n'est déjà plus de la liberté d'expression. Vous trouvez cela extrême ?
Mettons que nous acceptons la liberté d'expression pour tous, sauf pour les discours xénophobes, car c'est inacceptable, on est bien d'accord. Là, vous censurez déjà quelque chose, selon vos critères. Et ce n'est déjà plus de la liberté d'expression. Et puis, de fil en aiguille, vous allez décider que la liberté d'expression ne devrait pas s'appliquer aux blagues contre les Juifs. Ni contre les noirs. Ni contre les femmes. C'est dégradant. Continuons: Certains se sentiront offensés par les gros mots, d'autres par l'image de quelqu'un dévêtu ou une juppe courte, d'autres par une caricature, d'autres par des tatouages... Jusqu'où faut-il aller ? Ça n'a pas de fin.
Dès que vous commencez à grignoter la liberté d'expression (qu'elle soit verbale, écrite ou artistique), même d'une miette, ce n'est déjà plus de la liberté d'expression.
Et puis empêcher quelqu'un de s'exprimer, c'est le forcer à trouver un autre exutoire qui ne serait sans doute pas meilleur (Dans le meilleur des cas, passer par d'autres canaux que vous ne verrez plus). Plutôt que de mettre des oeillières, laissons-les s'exprimer au grand jour pour mieux les contrer.
4. Qu’est-ce que t’écoutes pour commencer ta journée ?
J'aime le calme, le matin. La musique - ou pire: les infos à la radio - m'agressent. Une fois que je suis bien réveillé, je met mon smartphone en lecture aléatoire pour aller au boulot. Il y a de tout, selon mes humeurs :-)
5. Est-ce que Twitter, Facebook et Google ont gagné ?
Oui. Ils ont gagné. Ils ont réussit, au bon moment, à proposer des services pré-mâchés. Les nouveaux internautes, n'ayant aucune culture de ce qu'est et permet internet, s'y sont engouffrés en masse. C'est maintenant une prison inconsciemment consentie dont ces boîtes entretiennent soigneusement les murs d'enceinte et la déco. Une prison dorée où les hamsters se complaisent.
Comme je l'ai dit (je me cite, quelle feignasse !): « Il fut une époque où je croyais qu'en éduquant les utilisateurs, on pourrait leur apprendre à communiquer par leurs propres moyens. Je constate mon échec: C'est peine perdue. Cela n'intéresse plus personne. Les ex-facebook iront bouffer au premier râtelier centralisé pré-mâché qui succèdera à Facebook. Rien ne changera. »
Ce qui est moche, c'est que ces sociétés:
- piocheront de plus en plus dans la vie privée des internautes pour gagner de l'argent.
- censurent (vraiment n'importe comment).
- collaborent avec les différents gouvernements (surveillance, censure, identification).
Malgré toutes les bonnes idées de décentralisation, l'avenir semble assuré pour la société de surveillance.
6. Est-ce que tu es pour ou contre la polygamie ?
La question n'a pas vraiment de sens. Pour ou contre l'homosexualité ? Pour ou contre les lits séparés ? Pour ou contre la cuisine au beurre ?
Je n'ai pas à juger des choix de vie des autres. Qui suis-je pour décider de la manière dont les autres doivent mener leur vie et être heureux ? Tant que cela ne rend malheureux personne, je ne vois pas où est le problème.
7. Quelle est la dernière série TV qui t’ai fait réfléchir ?
La TV ? Ce grand machin avec des images où on peut pas cliquer ?
8. La mémoire absolue, malédiction ou bénédiction ?
Malédiction.
Même si j'ai une mauvaise mémoire, je détesterais avoir une mémoire absolue. Déjà, je serais chiantissime pour les autres. Non sérieusement, vous détesteriez une personne comme ça dans votre entourage, non ?
Et puis l'oubli est un mécanisme cognitif nécessaire au fonctionnement du cerveau. Sans compter l'impact psychologique: Comment survivre si vous ne parvenez pas à oublier les moindres détails d'un traumatisme ? Ça serait une sacré malédiction.
9. Qu’est-ce qui te rend foi en l’humanité ?
Des actions ponctuelles que je peux voir ici et là, que ce soit le petit geste du quotidien d'un inconnu, ou les grands projets de personnalités brillantes qui veulent améliorer le sort de l'humanité (J'ai vu de très beaux projets chez TED, comme l'inventeur de cette bouteille qui filtre polluants et microbes de l'eau croupie, le projet d'accès global à la culture du fondateur d'archive.org, ou encore l'artiste JR qui ressoude des communautés défavorisées avec ses photos géantes).
C'est magnifique.
10. Si tu pouvais remonter dans le temps tu ferais quoi ? (Pro-Tip: Il y a une mauvaise réponse à cette question)
Je visiterais des époques incognito pour voir à quoi ressemblait leur style de vie, sans rien changer ! (Ce qui bien sûr est impossible puisque le simple fait d'y être changerait des choses :)
Ça serait passionnant: Visiter Paris dans les années 1900. Retourner au moyen-âge pour voir la vie quotidienne du peuple. Assister à des évènements historiques. Woua...
11. Qu’est-ce que tu voudrais faire dans l’immédiat ?
DORMIR !
 T'es trop jeune
T'es trop jeune
Lundi 18 fevrier 2013
Anadrark pousse une gueulante contre les internautes qui portent un jugement basé sur l'âge. Et il a raison.
Et c'est là que j'aime bien internet. On dépeint souvent certains internautes comme des jeunes qui ont trop de problèmes de communication pour réussir à aborder autrui dans la "vraie" vie, et qui utilisent internet (et son absence de contact et jugement physique) pour s'en affranchir.
C'est une vue réductrice de ces internautes, et une mauvaise appréciation de ce trait particulier d'internet. Ce n'est pas une faiblesse du réseau, c'est au contraire une force, car qu'on le veuille ou non, dans la vraie vie nous avons tous des a prioris sur les personnes que nous rencontrons, que cela soit sur l'aspect physique, l'habillement, la couleur de peau, la gestuelle, le ton de la voix, la culture ou le milieu social. Vous pouvez toujours vous gargariser sur votre ouverture d'esprit: Dans les faits, vous ne pourrez pas vous empêcher d'émettre un jugement au premier abord, et il y a des personnes que vous aborderez plus facilement que d'autres.
Internet vous interdit ce jugement. Vous communiquez de but en blanc, sans avoir la possibilité de vous poser la question. Au mieux, vous vous forgerez une opinion en vous basant sur les réponses, la tournure des phrases, le vocabulaire utilisé ou parfois le pseudo.
D'ailleurs certains internautes débutants ressentiront ce manque et auront très rapidement le réflexe de demander l'âge, mais avec le temps vous apprendrez à ignorer ce paramètre. J'ai eu des discussions très enrichissantes avec des ados de 14 ans ou des pépé de 70 ans, et - oui - j'avoue que je ne les aurai sans doute pas abordés avec autant de simplicité si j'avais pu les voir.
Je trouve finalement formidable cette "anonymisation" des discussions: Cela vous oblige à une certain ingénuité, à perdre la charge émotionnelle dans votre abord de l'autre, un peu comme certains enfants qui perdent cette méfiance naturelle et entament une discussion avec un inconnu. Ce n'est pas une infantilisation des communications, mais une naïveté saine, une remise à zéro de vos préjugés avant d'aborder l'autre.
(Putain j'écris des trucs bien, des fois.)
Retour sur ZeroBin
Lundi 18 fevrier 2013
Sur Twitter je suis tombé par hasard sur ça: « is there a way to search zerobin results by keyword? »
Cette question m'amuse beaucoup. Non, ce n'est bien sûr pas possible. C'est l'occasion de faire un petit retour sur ZeroBin:
- Tout d'abord, mon ZeroBin (installé sur sebsauvage.net/paste) est de plus en plus utilisé. C'est une bonne chose. Actuellement, 19847 textes y sont partagés. (Bien plus l'ont probablement été, puisque ceux ayant expiré ont été supprimés et que je n'en ai pas le compte ; Et j'ai fait exprès de mettre une date d'expiration par défaut d'un mois, afin que les données ne s'accumulent pas trop.).
- L'aspect ultra-minimaliste de l'application n'a pas du tout rebuté les utilisateurs, et j'en suis heureux. Je suis à cent lieux de Pastebin.com et ça me va très bien (pas de pub, pas 50 options, pas de bouton login facebook/twitter/google, pas d'enregistrement avec compte "pro", pas de captcha, pas 3 heures pour s'afficher.)
- Dans les liens ZeroBin publiques que j'ai pu trouver, les URLs cliquables ont largement été utilisées, aussi bien pour du http que pour des liens magnet (torrent). Good.
- Je n'ai reçu aucune injonction pour faire retirer du contenu.
- Ensuite, je vois que de nombreuses personnes discutent à travers ZeroBin (mais je ne peux bien sûr absolument pas savoir ce qui s'y dit :-). Il y a actuellement 821 discussions hébergées dans mon ZeroBin. Il y en a eu probablement bien plus également, les discussions expirées ayant été supprimées. Je n'ai jamais retrouvé les URLs de ces discussions dans le moindre moteur de recherche, ce qui signifie que ce sont des liens qui ont été échangés en privé et qui servent vraiment pour des discussions privées. C'est bien. C'était un des buts recherchés.
- Autre constatation: ZeroBin a merveilleusement tenu la charge, et le système de stockage par fichiers et sous-répertoires a très bien fait son office. (Je me suis inspiré de la manière de faire de Squid-cache).
- Je n'ai jamais retrouvé la moindre de trace du contenu de mes propres pastes ZeroBin dans un moteur recherche, ni même des discussions y attenant. Cela tient au fait que les moteurs de recherche n'interprètent pas le javascript. Ils sont donc "aveugle" face au contenu de ZeroBin. Cette situation me réjouit, et j'espère juste que les moteurs ne vont pas trop s'y mettre (Google a timidement commencé à interpréter le javascript, mais n'est toujours pas capable d'indexer le contenu des liens publiques ZeroBin). Il est donc actuellement impossible de rechercher dans ZeroBin avec un moteur de recherche, et c'est une excellente chose.
- Je constate également que divers ZeroBin sont installés un peu partout. C'est bien. Décentralisons les discussions privées. Plus de single-point-of-failure (ou plutôt single-point-of-surveillance/censure).
- Pour continuer sur une note moins réjouissante, je n'ai (honteusement) pas continué à faire évoluer ZeroBin. Certains attendent encore la coloration syntaxique ou la protection par mot de passe. Ça reste un logiciel très brut. Il y a encore du travail.
- Je remercie encore PeaceCopathe pour son excellente idée d'intégrer des discussions dans ZeroBin.
- Je suis heureux d'avoir intégré VizHash dans les discussions ZeroBin: C'est particulièrement pertinent dans ce cadre. Non seulement cela facilite le suivi des réponses, mais cela permet de fournir une identification (mais non une authentification) des posteurs sans révéler leur adresse IP, sans besoin de s'enregistrer au préalable et sans services extérieur (genre Gravatar).
- Enfin, je n'aurai jamais fait autant de bruit avec aussi peu de lignes de code (503 lignes de php/js seulement, si on enlève les commentaires): BBC, ArsTechnica, Slashdot, BoingBoing, Forbes, InformationWeek, Tom's Guide, H-Online, GHacks, HackerNews, 01Net, Clubic, Le Monde ... tout ça surtout grâce aux Anonymous qui se sont emparés de mon programme :-)
(Tiens d'ailleurs j'avais rappelé le journaliste de Forbes, mais je n'ai eu que son répondeur et il ne m'a jamais rappelé. Tant pis ! :)
Ça a été beaucoup d'émotions et de fun en très peu de lignes de code. Je vous recommande l'expérience: C'est jouissif d'être à la source d'autant de bordel avec si peu... mais de bordel constructif :-D
Mise à jour 19 février 2013: Wilfried P. me pose une question par email, et voici ma réponse:
Je vois en effet de temps en temps passer des liens ZeroBin postés par les Anonymous.
Je pourrais effectivement décider de juger le contenu de ces pastes, et décider de les supprimer. Mais je ne le ferai pas, sauf sur injonction judiciaire. Pourquoi ? Je refuse de me porter en juge sur la légalité de ce qui est posté. De toute manière, quelle serait ma légitimité en la matière ? Je n'ai fait aucune étude de droit.
En plus de l'aspect "légale" il y a l'aspect "moral". Certaines opérations des Anonymous sont illégales, mais au contraire très morales (par exemple faire bouger les choses pour les viols dans l'Ontario). Dans l'autre sens, certaines entreprises font des choses qui sont parfaitement légales, mais franchement immorales... à mon sens.
Encore une fois, le jugement de la "moralité" d'une action est tout à fait personnel.
Ne m'estimant pas le droit de juger de la légalité et de la moralité de ce qui est posté (car cela serait un jugement tout à fait personnel et arbitraire), je préfère ne rien modérer du tout. Et j'ai créé ZeroBin dans ce but: Me poser en pur hébergeur de données, avec aucune possibilité d'y mettre le nez pour les juger.
Le web est morcelé ? Merci le W3C !
Mercredi 21 novembre 2012

Rhhâââ.... je déteste vraiment quand les sites web font ça. On se croirait revenu à l'époque des sites conçus pour IE. Mon navigateur ne supporte pas le «web audio avancé» ? Hein ? Ça ne serait pas - par hasard - parce que le site utilise le format MP3, et que Firefox et Opera ont refusé de payer la licence MP3 ? L'audio dans mon navigateur fonctionne très bien, merci.
Et à qui doit-ton cette pseudo-incompatibilité digne de la grande gueguerre Netscape/IE des années 90 ? Au W3C qui a décidé de ne pas imposer de codecs lors des comités de standardisation d'HTML5.
Voilà, maintenant on est dans la merde avec des sites qui ne marchent que dans tel ou tel navigateur. Bravo. Merci, le W3C, d'avoir contribué à morceler le web (C'est pas comme si Vorbis était gratuit, libre de droit, de meilleure qualité que le MP3 et existait de puis 12 ans.)
Résumé du support des codecs audio dans les navigateurs:
| Vorbis | MP3 | WAV | |
| Safari | x | x | |
| IE | x | x | |
| Chrome | x | x | |
| Firefox | x | x | |
| Opera | x | x |
Putain, Apple et Crosoft, vous attendez quoi pour supporter le format Vorbis ? (Ou même Opus, hein, vu que Microsoft a participé à la création de ce codec libre.)
- Coût annuel forfaitaire de la licence MP3: 15 000 dollars.
- Coût de la licence pour un décodeur MP3 par unité (oui oui, on parle bien de logiciel, non de matériel): 0,75 dollars.
- En 2005 (il y a 7 ans !), Firefox avait déjà été téléchargé 75 millions de fois, donc: 75 000 000 x 0,75 + 15 000 = 56 265 000
La licence MP3 couterait au bas mot 56 millions de dollars à la fondation Mozilla. Meh. J'imagine bien que pour Apple ou Microsoft, 56 millions c'est un pet de capucin, mais il ne faut quand même pas pousser mémé dans les orties.
Attendez, ce n'est pas fini ! Maintenant ajoutez la même merde avec les codecs vidéo (H264, Theora, VP8...), et saupoudrez avec la scission W3C/WhatWG sur le standard HTML5, de diverses merdes sur les CSS, et les webmasters de la planète se préparent de jolis maux de tête dans les années à venir. Remarquez au moins on verra la mort de Flash et Silverlight, c'est déjà ça (à moins que Microsoft décide encore une fois de réinventer la roue (ActiveX anyone ?)).
Tous ces Apple, Google et Microsoft ont beau participer en grandes pompes aux divers comités du W3C, ça sonne un peu creu. Je doute sérieusement de leur volonté de standardiser et unifier le web. Ce n'est pas le W3C qui est en cause, mais certains de ses participants.
Je vais le redire: Certains participants du W3C œuvrent activement à construire et promouvoir un web qui ne fonctionne que dans leur propre navigateur.
Mozilla, Opera, vous avez toute ma gratitude pour vos efforts à respecter les standards et œuvrer à un web ouvert et qui marche bien chez tout monde. Mozilla et Opera bossent dans l'intérêt les internautes et webmasters, IE/Chrome/Safari ne marchent que pour leur gueule (portefeuille de brevets, écosystème, OS, marché). Et ce sont les webmasters et internautes qui vont en souffrir. Dommage, le web aurait pu être techniquement beau et unifié.
Ah ça, IE/Chrome/Safari peuvent bien se gargariser de leur respect des standards: En sous-marin, ils introduisent des fonctionnalités supplémentaires spécifiques et incitent les webmasters à les adopter, provoquant de fait un morcellement. Mais c'est pas de leur faute ! Eux ils respectent les standards. C'est la faute aux webmasters qui utilisent abusivement ces extensions de la norme (genre: -webkit-* en CSS).
...WAIT. Ce genre d'argument pourrait presque être crédible ci ces vendeurs ne faisaient pas une promotion massive de leur navigateur maison et de leurs fonctionnalités spécifiques, genre: chanson de Ok Go sponsorisée par Google Chrome, présentée sur un site ne marchant que avec Chrome, ou bien les Chrome Labs, Chrome Experiments ou carrément son Chrome Web Store qui ambitionne d'être à lui tout seul une plateforme de distribution et exécution de logiciels utilisant son Native Client qui ne marche... que dans Chrome.




Ou Apple qui arrive à afficher - sur sa page de promotion des standards du web - une jolie popup:

Chez Microsoft c'est à peine plus discret:


Quand ce n'est pas carrément un moyen de vendre son nouveau système d'exploitation (si vous n'utilisez pas notre nouvel OS, vous ne profiterez pas des nouvelles merveilles du web):

(La seule chose que vous avez sur la page de téléchargement d'Internet Explorer, c'est un gros bouton «Rencontrez Windows». Et après Microsoft nous gratifie d'une jolie publicité pour le nouvel IE, qui est soit-disant gratuit.)
Tout cela rappelle la grand époque:

Ou comment se la jouer "ouverture"/"respect des standards" tout en poussant à mort son propre navigateur, à son propre bénéfice.
Je dis et je le pense: IE (Microsoft), Chrome (Google) et Safari (Apple) sont toxiques pour le web. Je ne jouerai pas leur jeu en utilisant leur navigateur. En quelque sorte, je vote technologiquement. Et je vote pour un web ouvert. Prise individuellement, mon action peut paraître ridicule, mais comme dans tout vote chaque voix compte. Faites votre choix. Les machins qui brillent ou votre liberté technologique.
Donc, pour en revenir au site qui a provoqué mon ire (oui là depuis le début de l'article, je digresse), donc - disais-je avant de m'interrompre moi-même comme le faisait Desprogres1) - après voir lancé Chrome (agreû), j'ai essayé le site « The Infinite Jukebox »: Vous n'êtes pas encore lassé d'écouter votre chanson préférée en boucle ? Ce site peut réussir à vous en dégouter en créant une version de votre chanson qui joue indéfiniment. Par quel miracle ? En repérant les segments identiques dans la chansons et en y "sautant" aléatoirement. Ça marche plus ou moins bien selon les musiques, mais le concept est amusant. Vous pouvez uploader le MP3 de votre choix. (Le cercle représente la durée de votre chanson. Les lignes au milieu représentent des similarités détectées par le logiciel: L'application va donc faire aléatoirement des sauts vers ces segments quasi-identiques.)
Amusez-vous bien, et fuck IE/Chrome/Safari.
1) Je peux en rajouter une couche ou vous en avez déjà marre ?
 Ma malédiction de développeur
Ma malédiction de développeur
Mardi 20 novembre 2012
C'est un article de Maniac Geek qui m'a fait venir cela à l'esprit.
En tant que développeur et joueur depuis longtemps (30 ans, hein, quand même), j'ai un problème: Je finis par "voir" ou "ressentir" les mécanismes, la logique de fonctionnement des jeux à force d'y jouer (Et je ne suis probablement pas le seul). J'arrive à imaginer les algos utilisés, je traque instinctivement les glitchs d'affichage ou la cassure visible des polygones sur un objet pas assez tesselated, imagine les algos utilisés pour la génération procédurale et l'IA des ennemis ou devine le découpage des hitbox. Quand je regarde une vidéo, mon cerveau cherche instinctivement les artefacts de compression. C'est plus fort que moi.
Et du coup, à imaginer le travail des développeurs pour traiter tel ou tel point précis, ça casse un peu la magie. C'est ma malédiction.
C'est en partie ce qui fait que je joue moins à Minecraft qu'avant. J'y ai tellement joué et "ressenti" le jeu que la magie des premières explorations est éventée: Les algos - ou du moins leurs résultats - me sont devenus trop visibles. Je me suis même surpris à explorer des réseaux de caverne rien que pour essayer de trouver des formes atypiques, différentes de ce que le générateur procédural produit habituellement. J'en suis à explorer les extrêmes la courbe gaussienne. Doh ! Fichu cerveau.
Oh je ne dis pas: J'apprécie les graphismes d'un nouveau jeu, l'originalité de son gameplay et sa profondeur (ou son absence, le plus souvent). Ça peut passer agréablement le temps. Mais l'illusion ne dure jamais.
Du coup, je suis plus enclin à jouer à des jeux comme Dwarf Fortress qui sont d'une complexité ahurissante, ou des jeux où qu'il faut maîtriser progressivement (Urban Terror, Dustforce) mais ces genres de jeux nécessitent un certain investissement de temps que je ne peux plus me permettre.
Si quelqu'un décide un jour de faire un mashup de Minecraft (pour sa 3D, sa génération procédurale et son accessibilité) avec Dwarf Fortress (pour sa formidable profondeur de jeu), je n'aurai qu'une chose à dire:

Les DRM tuent la culture
Lundi 22 octobre 2012
Encore une semaine qui passe, encore exemple d'oblitération de la culture par les DRM: Cet utilisateur de Kindle a vu la totalité des livres qu'il avait achetés soudainement disparaître de son Kindle (livre électronique d'Amazon). Ils ont été effacés à distance par Amazon.
La justification d'Amazon ? Son compte serait lié à un autre compte qui aurait violé les règles Amazon.
De quel compte s'agit-il ? En quoi est-il relié à son compte actuel ? Quelle règle a été violée ? Amazon refuse de répondre. On se retrouve comme face au géant Google: Un mur. Et aucun recours.
Les DRM ne protègent pas la culture, ils la tuent.
Que ce soit dans des livres, des films, des musiques ou des logiciels, refusez les DRM.
EDIT 24 oct.: Amazon a discrètement fait machine arrière, sans doute parce que ça commençait à faire trop de buzz (après lui avoir gentiment dit d'aller acheter ses livres ailleurs). Le problème des DRM reste entier.
Et Orange enterra la neutralité du net
Jeudi 11 octobre 2012
EDIT: (De l'intérêt de ne pas publier trop vite): Orange publie un démenti (voir aussi chez Clubic): Le site "La lettre A" aurait mal interprété les propos d'Orange. Il s'agirait de l'offre "Préférence" d'Orange... ce qui n'exclue pas la présence du DPI malgré les dires d'Orange.
Je n'ai jamais été fan d'Orange, et mois après mois ils me donnent des raisons de ne jamais aller chez eux.
Cette image circule sur le net depuis des années. C'est une (sinistre) blague sur la neutralité du réseau, une fiction sur ce qui se passerait si la neutralité du net était brisée.
{kind=link}
Et bien il semblerait qu'Orange s'oriente exactement vers cela pour ses connexion ADSL. Imaginez: Vous avez un abonnement standard. Vous voulez des débits tolérables sur YouTube ? Payez un supplément. Vous voulez utiliser Skype et faire de la VOIP ? Payez un autre supplément.
Dit autrement, Orange pourrait vous facturer le droit d'accéder (décemment) à des sites web et d'utiliser des technologies qui ne lui appartiennent pas. Le rêve de tous les FAI véreux. (Encore une fois, cette information est à mettre au conditionnel.)
Et avec quelle technologie ? Avec du DPI bien sûr. Après avoir nié l'avoir déployé sur son réseau, Orange admet maintenant que c'est grâce à cette technologie qu'il pourra vous vendre son accès internet bridé. Et histoire de faire dans le glauque, ils utilisent des équipements de la société Qosmos qui s'est déjà rendu célèbre pour avoir vendu son matériel de surveillance à des dictatures.
Plus que jamais: Il y a internet, et internet par Orange.

Notez que les autres FAI ne sont pas forcément plus glorieux sur le sujet: Même s'ils n'en sont pas à ce niveau, ils brident les débits sur certains sites ou protocoles (par exemple YouTube chez Free).
Je pense qu'au final, prendre un VPN à l'étranger vous permettra peut-être d'avoir de meilleurs débits... à moins bien sûr qu'ils brident par défaut tous les protocoles de VPN. C'est moche, c'est très moche.
EDIT 15 oct. 2012: Pas de DPI chez Orange ? Vraiment ?
L'hypocrisie d'Apple
Vendredi 05 octobre 2012
Apple a forcé un enseignant à retirer le mot "Libre" d'un ouvrage gratuit qu'il avait publié pour l'iPad.
Apple, GROS HYPOCRITE. Le cœur même de ton iOs et de ton MacOSX est du logiciel libre, bordel (noyau Mach + composants BSD).
Tu as vu la quantité de logiciels libres qui entrent dans la composition de MacOSX ?: Apache, autoconf, awk, bash, bc, BerkeleyDB, bind9, bison, bsdiff, bzip2, clamav, cron, cups, curl, cvs, emacs, fetchmail, gdb, gnudiff, gnuzip, gnumake, gnutar, grep, groff, hunspell, libpng, libjpeg, libxml2, man, nano, ncurses, netcat, OpenSSH, pcre, perl, postfix, PostregreSQL, procmail, Python, rsync, SpamAssassin, SQLite, subversion, tcl, tcpdump, vim, zlib...
Ça va, ça t'en touche une sans bouger l'autre de refuser le simple mot "libre" sur un livre ?

Héberger des vidéos sur son propre serveur... sans le tuer
Mercredi 03 octobre 2012
YouTube censure à tour de bras:
- Entre les robots de Google qui censurent idiotement les vidéos (même des chants d'oiseaux).
- Les industriels de la culture qui envoient des mises en demeure à Google, souvent totalement injustifiées, parfois à leur propre profit.
- les pays qui censurent certaines vidéos (quand ils ne coupent pas intégralement YouTube).
- et YouTube lui-même qui commence à censurer selon le bon vouloir des pays.
Il faut sérieusement réfléchir à héberger ses vidéos soi-même. (Mitsukarenai est un expert sur le sujet, alors ma petite diatribe du jour va sûrement le faire sourire.)
Seulement voilà, héberger soi-même des vidéos pose des problèmes épineux:- Cela consomme votre bande passante vitesse grand V. Certains hébergeurs vous factureront chèrement les dépassements, d'autres couperont tout simplement votre site.
- Si votre vidéo devient populaire, vous aurez des problèmes de débit (votre hébergeur peinant à servir la vidéo à tout le monde). Vous n'avez pas les CDN de YouTube pour répartir la vidéo sur différents serveurs dans le monde. Et vous n'avez probablement pas les moyens de vous payer des CDN Akamai.
- Enfin il faut que vous gériez vous-même la compatibilité entre navigateurs: Utilisation du tag video d'HTML5 ou non, codecs vidéo supportés... avouez, c'est chiant.
J'ai fini par trouver une solution très simple et qui ne tue pas votre serveur. Voici comment procéder:
- Encodez vos vidéos en WebM et MP4, et placez-les quand même sur votre serveur.
- Ajoutez un fichier .htaccess pour servir les vidéos avec le bon type MIME:
AddType video/mp4 .mp4
AddType video/webm .webm - Prenez le lecteur opensource Video.js: Il utilise HTML5/balise video et javascript pour lire la vidéo WebM. C'est très simple:
<script src="video-js/video.js">< /script>
<script>_V_.options.flash.swf = "video-js/video-js.swf";< /script>
<video id="test_video_1" class="video-js vjs-default-skin" controls preload="none" width="854" height="480"
poster="http://mondomaine.com.nyud.net/videos/video1_miniature.jpg" data-setup="{}">
<source src="http://mondomaine.com.nyud.net/videos/video1.webm" type='video/webm' />
<source src="http://mondomaine.com.nyud.net/videos/video1.mp4" type='video/mp4' />
</video> - Si le navigateur ne supporte pas WebM ou HTML5, Video.js bascule sur Flash et MP4, ce qui assure une compatibilité avec pratiquement tous les navigateurs.
- Comme vous pouvez le voir dans les balises
source, ajoutez .nyud.net au nom de domaine dans les URLs de vos vidéos.
C'est tout: Video.js vous assure que le lecteur marchera dans pratiquement tous les navigateurs. Les navigateurs supportant HTML5+WebM l'afficheront directement (Firefox, Opera, Chrome...), les autres (Safari, IE...) se rabattront sur MP4 (soit en HTML5 aussi, soit via Flash).
Vous avez remarqué le ".nyud.net" ? Par le simple fait d'appeler votre vidéo à travers cette URL, le CDN CoralCache ira lire une seule fois la vidéo de votre serveur et la répliquera dans le monde au fur et à mesure qu'elle est consultée. Plus de problème de bande passante: Ce sont leurs serveurs qui fournissent la vidéo, et non le vôtre. Et plus de problème de débit non plus: Avec 300 serveurs répartis dans le monde, même des internautes éloignés pourront lire la vidéo sans coupure. (CoralCache est gratuit depuis 8 ans et sans contrepartie.)
Accessoirement, cela fait la nique aux limites de débit posées artificiellement par les fournisseurs d'accès sur des sites comme YouTube (coucou Free, coucou Orange).
Petit bémol de cette solution: Les fichiers sont limités à 50 Mo. Au delà de 50 Mo, CoralCache ne fait plus office de cache et renvoie vers votre serveur en direct.
Voilà le résultat (j'ai mis la vidéo du trailer du jeu Dustforce - me gusta).
Très simple à mettre en place, compatible (pratiquement) tous navigateurs, vous gardez le contrôle de l'hébergement de la vidéo, ça ne tue pas votre bande passante et ça assure un bon débit n'importe où dans le monde. Chouette, non ? Avec ça, on a plus vraiment besoin de YouTube pour publier ses vidéos... à part un peu d'espace sur son hébergement. Il est reste quand même la facilité de publication sur YouTube et ses petits outils (commentaires, stabilisation de vidéo, plusieurs résolutions de vidéo fournies, etc.) qui peuvent faire préférer ce dernier.
Quant à la liberté d'expression, jusqu'à présent je n'ai jamais vu CoralCache censurer quoi que ce soit. Au pire, le risque est que votre vidéo soit illisible si le domaine nyud.net est bloqué, mais ce n'est pas pire que YouTube. Au moins la vidéo est (virtuellement) "chez vous".
De rien, ça me fait plaisir :-)
EDIT 5 oct.: Et crotte, je viens de m'apercevoir que CoralCache, pour le moment, ne met en cache que les fichiers de moins de 50 Mo. :-/ Flûte. Si le fichier fait 50 Mo ou plus, il y a une redirection transparente vers votre site (avec un ?coral-no-serve dans l'URL). Ils sont en train de travailler à une manière plus efficace de mettre en cache les gros fichiers.
Pour consulter les articles précédents, utilisez le petit calendrier en haut de page.
Publié avec le moteur de blog BlogoText
Les commentaires sont fermés sur ce blog.
Cette création est mise à disposition sous un contrat Creative Commons
exception faite des extraits de textes et images restant la propriété de leurs auteurs respectifs.
Toute copie partielle ou totale de ce site doit mentionner http://sebsauvage.net
Billets précédents:
| Lu | Ma | Me | Je | Ve | Sa | Di |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |